Category: AI Category
-

The vast majority (92%) of marketing professionals are using AI in their day-to-day operations, turning it from a buzzword into a workhorse. According to SAP Emarsys – which took the pulse of over 10,000 consumers and 1,250 marketers – while businesses are seeing real benefits from AI, shoppers are becoming increasingly distrustful, especially when it…
-
In this article, you will learn: • The fundamental difference between traditional regression, which uses single fixed values for its parameters, and Bayesian regression, which models them as probability distributions. Source link
-
When working with machine learning on structured data, two algorithms often rise to the top of the shortlist: random forests and gradient boosting . Source link
-
Data merging is the process of combining data from different sources into a unified dataset. Source link
-
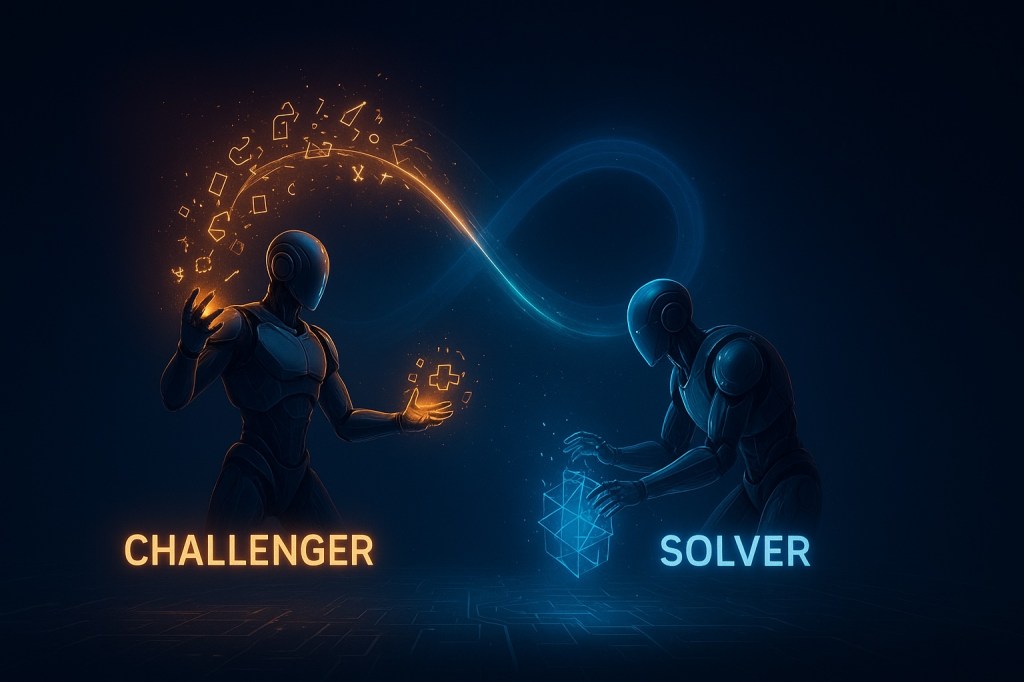
Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now A new training framework developed by researchers at Tencent AI Lab and Washington University in St. Louis enables large language models (LLMs) to improve themselves without requiring any human-labeled data. The technique, called R-Zero,…
-

Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now Nvidia reported $46.7 billion in revenue for fiscal Q2 2026 in their earnings announcement and call yesterday, with data center revenue hitting $41.1 billion, up 56% year over year.…
-

Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now OpenAI adds to an increasingly competitive AI voice market for enterprises with its new model, gpt-realtime, that follows complex instructions and with voices “that sound more natural and expressive.”…
-

Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now Nous Research, a secretive artificial intelligence startup that has emerged as a leading voice in the open-source AI movement, quietly released Hermes 4 on Monday, a family of large…
-

Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now OpenAI and Anthropic may often pit their foundation models against each other, but the two companies came together to evaluate each other’s public models to test alignment. The companies…
-

Agentic AI is being talked about as the next major wave of artificial intelligence, but its meaning for enterprises remains to be settled. Capgemini Research Institute estimates agentic AI could unlock as much as US$450 billion in economic value by 2028. Yet adoption is still limited: only 2% of organisations have scaled its use, and…