In this article, you will learn five practical prompt compression techniques that reduce tokens and speed up large language model (LLM) generation without sacrificing task quality.
Topics we will cover include:
- What semantic summarization is and when to use it
- How structured prompting, relevance filtering, and instruction referencing cut token counts
- Where template abstraction fits and how to apply it consistently
Let’s explore these techniques.
Prompt Compression for LLM Generation Optimization and Cost Reduction
Image by Editor
Introduction
Large language models (LLMs) are mainly trained to generate text responses to user queries or prompts, with complex reasoning under the hood that not only involves language generation by predicting each next token in the output sequence, but also entails a deep understanding of the linguistic patterns surrounding the user input text.
Prompt compression techniques are a research topic that has lately gained attention across the LLM landscape, due to the need to alleviate slow, time-consuming inference caused by larger user prompts and context windows. These techniques are designed to help decrease token usage, accelerate token generation, and reduce overall computation costs while keeping the quality of the task outcome as much as possible.
This article presents and describes five commonly used prompt compression techniques to speed up LLM generation in challenging scenarios.
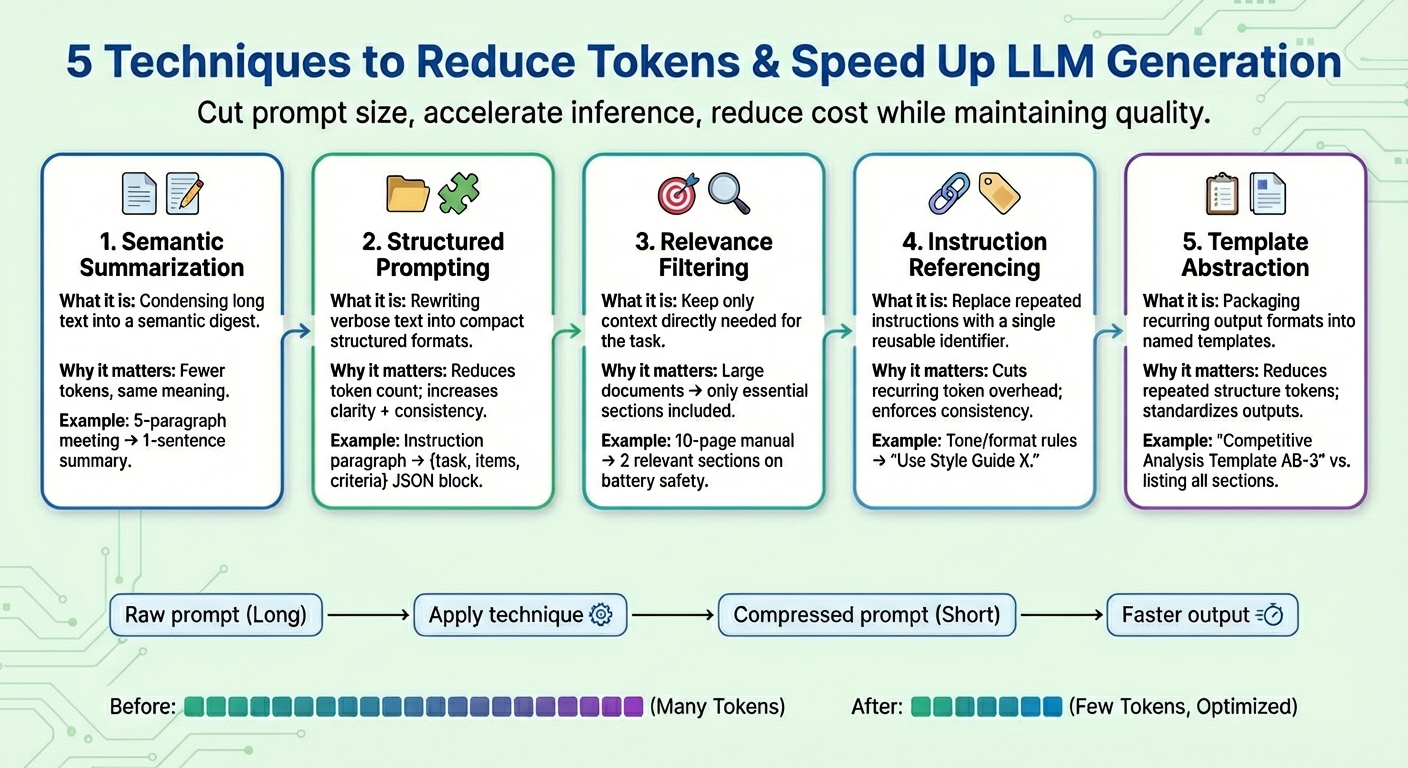
1. Semantic Summarization
Semantic summarization is a technique that condenses long or repetitive content into a more succinct version while retaining its essential semantics. Rather than feeding the entire conversation or text documents to the model iteratively, a digest containing only the essentials is passed. The result: the number of input tokens the model has to “read” becomes lower, thereby accelerating the next-token generation process and reducing cost without losing key information.
Suppose a long prompt context consisting of meeting minutes, like “In yesterday’s meeting, Iván reviewed the quarterly numbers…”, summing up to five paragraphs. After semantic summarization, the shortened context may look like “Summary: Iván reviewed quarterly numbers, highlighted a sales dip in Q4, and proposed cost-saving measures.”
2. Structured (JSON) Prompting
This technique focuses on expressing long, smoothly flowing pieces of text information in compact, semi-structured formats like JSON (i.e., key–value pairs) or a list of bullet points. The target formats used for structured prompting typically entail a reduction in the number of tokens. This helps the model interpret user instructions more reliably and, consequently, enhances model consistency and reduces ambiguity while also reducing prompts along the way.
Structured prompting algorithms may transform raw prompts with instructions like Please provide a detailed comparison between Product X and Product Y, focusing on price, product features, and customer ratings into a structured form like: {task: “compare”, items: [“Product X”, “Product Y”], criteria: [“price”, “features”, “ratings”]}
3. Relevance Filtering
Relevance filtering applies the principle of “focusing on what really matters”: it measures relevance in parts of the text and incorporates in the final prompt only the pieces of context that are truly relevant for the task at hand. Rather than dumping entire pieces of information like documents that are part of the context, only small subsets of the information that are most related to the target request are kept. This is another way to drastically reduce prompt size and help the model behave better in terms of focus and boosted prediction accuracy (remember, LLM token generation is, in essence, a next-word prediction task repeated many times).
Take, for example, an entire 10-page product manual for a cellphone being added as an attachment (prompt context). After applying relevance filtering, only a couple of short relevant sections about “battery life” and “charging process” are retained because the user was prompted about safety implications when charging the device.
4. Instruction Referencing
Many prompts repeat the same kinds of directions over and over again, e.g., “adopt this tone,” “reply in this format,” or “use concise sentences,” to name a few. Instruction referencing creates a reference for each common instruction (consisting of a set of tokens), registers each one only once, and reuses it as a single token identifier. Whenever future prompts mention a registered “common request,” that identifier is used. Besides shortening prompts, this strategy also helps maintain consistent task behavior over time.
A combined set of instructions like “Write in a friendly tone. Avoid jargon. Keep sentences succinct. Provide examples.” could be simplified as “Use Style Guide X.” and then be reused when the equivalent instructions are specified again.
5. Template Abstraction
Some patterns or instructions often appear across prompts — for instance, report structures, evaluation formats, or step-by-step procedures. Template abstraction applies a similar principle to instruction referencing, but it focuses on what shape and format the generated outputs should have, encapsulating those common patterns under a template name. Then template referencing is used, and the LLM does the job of filling the rest of the information. Not only does this contribute to keeping prompts clearer, it also dramatically reduces the presence of repeated tokens.
After template abstraction, a prompt may be turned into something like “Produce a Competitive Analysis using Template AB-3.” where AB-3 is a list of requested content sections for the analysis, each one being clearly defined. Something like:
Produce a competitive analysis with four sections:
- Market Overview (2–3 paragraphs summarizing industry trends)
- Competitor Breakdown (table comparing at least 5 competitors)
- Strengths and Weaknesses (bullet points)
- Strategic Recommendations (3 actionable steps).
Wrapping Up
This article presents and describes five commonly used ways to speed up LLM generation in challenging scenarios by compressing user prompts, often focusing on the context part of it, which is more often than not the root cause of “overloaded prompts” causing LLMs to slow down.
Leave a Reply